Exhaustive Search - R Package
A high-performance implementation of an exhaustive feature selection in R.
The package (v1.0.1) is available on CRAN.
Visit GitHub Page
Motivation
Finding the optimal set of features for a prediction model is a widely studied problem. Multiple so-called suboptimal feature-selection techniques exist, which try to navigate through the feature space in an intelligent way to come up with a predictive subset of features.
The main reason these algorithms exist is that an optimal feature selection (ie. evaluating all combinations) is typically infeasible. This R package tries to broaden the horizon on that a little bit. With an efficient implementation and suitable set of model and evaluation settings, billions of feature sets can be evaluated in a reasonable time.
The goal was to have an easy to use interface in R, to perform an exhaustive search, which returns the top feature sets and their performance.
Development
For the best performance, I needed to use a fast programming language. I chose C++, as it nicely interacts with R. Another motivation was to learn a little bit more about this advanced programming language. I wanted to implement the simple OLS regression, but also Logistic Regression, which turned out to be a bit of a challenge. As performance measures I chose to implement the MSE and AUC, as both can be computed fast and easy.
The development had a lot of smaller and bigger challenges:
Memory management
Dealing with these orders of magnitude makes the most ordinary things difficult. For instance, just looping over all combinations to evaluate them is not trivial, as you cannot just compute all combinations first and then access them by index. So i needed a function that gives me the i-th combination of N over k total combinations by index. Storing the performance of multiple billions of models is of course also not feasible. The solution to this is a running top-n list. As normally you dont need the performance and ranking of all models, we can simplify it by only storing the top n combinations. Thus, after every iteration, the results are added to the top list, which is then sorted by performance and truncated to the top n elements.
Multithreading in C++
For better performance, we need parallelization. In C++ more efficiently threading. Splitting stuff up into batches makes the problems of memory management even more complicated. Which thread executes which combinations, and how can different threads write into the same top-n list at a certain memory address without causing overwrites, yada yada…
Fitting a Logistic Regression
Contrary to OLS, the Logistic Regression has closed form. So I needed a numeric optimizer to compute it. That was quite a rabbit hole… I grabbed some statistics textbook, found the form of the Log-Likelihood that I needed to optimize. Then I looked into how R optimizes it and found that it (of course) not just uses some simple gradient descent method, but the a tiny bit more complicated Limited-memory Broyden-Fletcher-Goldfarb-Shanno method… I found a C port of the FORTRAN implementation of this L-BFGS method, which i somehow got to run in my C++ code. I tested the results and it matched what I got in R up to the last decimal point. I must say i am quite proud about getting this to work :-P. It might be the most advanced stuff I have ever done so far.
Results
The final R package was accepted in CRAN and this can be simply installed in R.
> install.packages("ExhaustiveSearch")
The main function ExhaustiveSearch() uses the typical formula and data
structure, which is also used in lm() or glm().
> library(ExhaustiveSearch)
> data(mtcars)
> ExhaustiveSearch(mpg ~ ., data = mtcars, family = "gaussian")
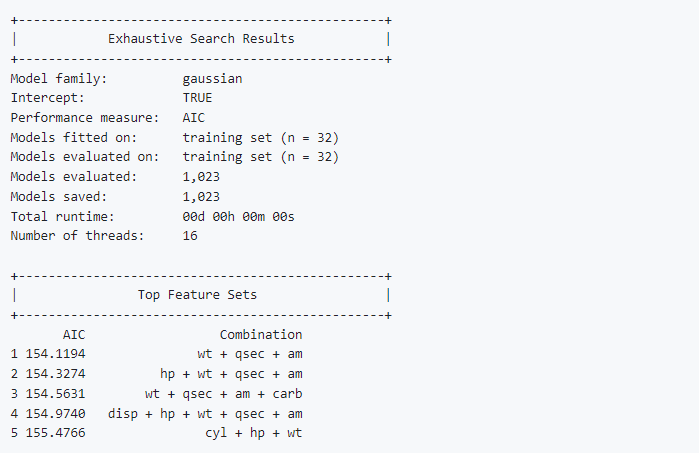
+-------------------------------------------------+
| Exhaustive Search Results |
+-------------------------------------------------+
Model family: gaussian
Intercept: TRUE
Performance measure: AIC
Models fitted on: training set (n = 32)
Models evaluated on: training set (n = 32)
Models evaluated: 1,023
Models saved: 1,023
Total runtime: 00d 00h 00m 00s
Number of threads: 16
+-------------------------------------------------+
| Top Feature Sets |
+-------------------------------------------------+
AIC Combination
1 154.1194 wt + qsec + am
2 154.3274 hp + wt + qsec + am
3 154.5631 wt + qsec + am + carb
4 154.9740 disp + hp + wt + qsec + am
5 155.4766 cyl + hp + wt
A local benchmark on an AMD Ryzen 7 1700X on a data set of 500 observations resulted in the following performances:
Linear Regression: 45000 models/threadsec
Logistic Regression: 2500 models/threadsec
Therefore, on a typical home-PC setup (16 threads), one could expect to be able to evaluate 2,592,000,000 linear regression models per hour. For logistic regression, this number would be 120,000,000 models per hour.
Further Information
https://github.com/RudolfJagdhuber/ExhaustiveSearch
https://cran.r-project.org/web/packages/ExhaustiveSearch/index.html